


The ongoing proliferation of AI coding tools is not only boosting developers’ efficiency, it also signals a future where AI will generate a growing share of all new code. GitHub CEO Thomas Dohmke (opens in new tab) predicted as much in 2023, when he said that “sooner than later, 80% of the code is going to be written by Copilot.”
Both large and small software companies are already heavily using AI to generate code. Y Combinator’s Garry Tan (opens in new tab) noted that 95% of code for a quarter of Y Combinator’s latest batch of startups was written by large language models.
In fact, most developers spend the majority of their time debugging code, not writing it. As maintainers of popular open-source repositories, this resonates with us. But what if an AI tool could propose fixes for hundreds of open issues, and all we had to do was approve them before merging? This was what motivated us to maximize the potential time savings from AI coding tools by teaching them to debug code.
By debugging we mean the interactive, iterative process to fix code. Developers typically hypothesize why their code crashed, then gather evidence by stepping through the program and examining variable values. They often use debugging tools like pdb (Python debugger) to assist in gathering information. This process is repeated until the code is fixed.
Today’s AI coding tools boost productivity and excel at suggesting solutions for bugs based on available code and error messages. However, unlike human developers, these tools don’t seek additional information when solutions fail, leaving some bugs unaddressed, as you can see in this simple demo of how a mislabeled column stumps today’s coding tools (opens in new tab). This may leave users feeling like AI coding tools don’t understand the full context of the issues they are trying to solve.
Introducing debug-gym
A natural research question emerges: to what degree can LLMs use interactive debugging tools such as pdb? To explore this question, we released debug-gym (opens in new tab) – an environment that allows code-repairing agents to access tools for active information-seeking behavior. Debug-gym expands an agent’s action and observation space with feedback from tool usage, enabling setting breakpoints, navigating code, printing variable values, and creating test functions. Agents can interact with tools to investigate code or rewrite it, if confident. We believe interactive debugging with proper tools can empower coding agents to tackle real-world software engineering tasks and is central to LLM-based agent research. The fixes proposed by a coding agent with debugging capabilities, and then approved by a human programmer, will be grounded in the context of the relevant codebase, program execution and documentation, rather than relying solely on guesses based on previously seen training data.
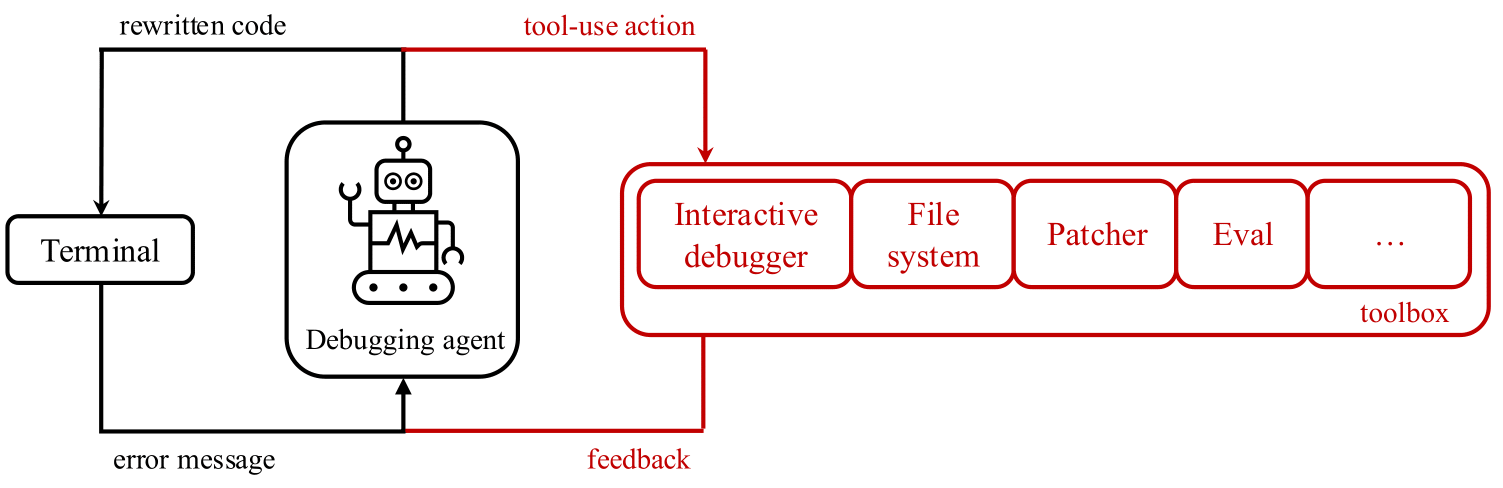
Debug-gym is designed and developed to:
- Handle repository-level information: the full repository is available to agents in debug-gym, allowing them to navigate and edit files.
- Be robust and safe: to safeguard both the system and the development process, debug-gym runs code within sandbox Docker containers. This isolates the runtime environment, preventing harmful actions while still allowing thorough testing and debugging.
- Be easily extensible: debug-gym was conceived with extensibility in mind and provides practitioners with the possibility of easily adding new tools.
- Be text-based: debug-gym represents observation information in structured text (e.g., JSON format) and defines a simple syntax for text actions, making the environment fully compatible with modern LLM-based agents.
With debug-gym, researchers and developers can specify a folder path to work with any custom repository to evaluate their debugging agent’s performance. Additionally, debug-gym includes three coding benchmarks to measure LLM-based agents’ performance in interactive debugging: Aider for simple function-level code generation, Mini-nightmare for short, hand-crafted buggy code examples, and SWE-bench for real-world coding problems requiring a comprehensive understanding of a large codebase and a solution in the format of a GitHub pull request.
To learn more about debug-gym and start using it to train your own debugging agents, please refer to the technical report (opens in new tab) and GitHub (opens in new tab).
Early experimentation: promising signal
For our initial attempt to validate that LLMs perform better on coding tests when they have access to debugging tools, we built a simple prompt-based agent and provided it with access to the following debug tools: eval, view, pdb, rewrite, and listdir. We used nine different LLMs as the backbone for our agent. Detailed results can be found in the technical report (opens in new tab). (opens in new tab)
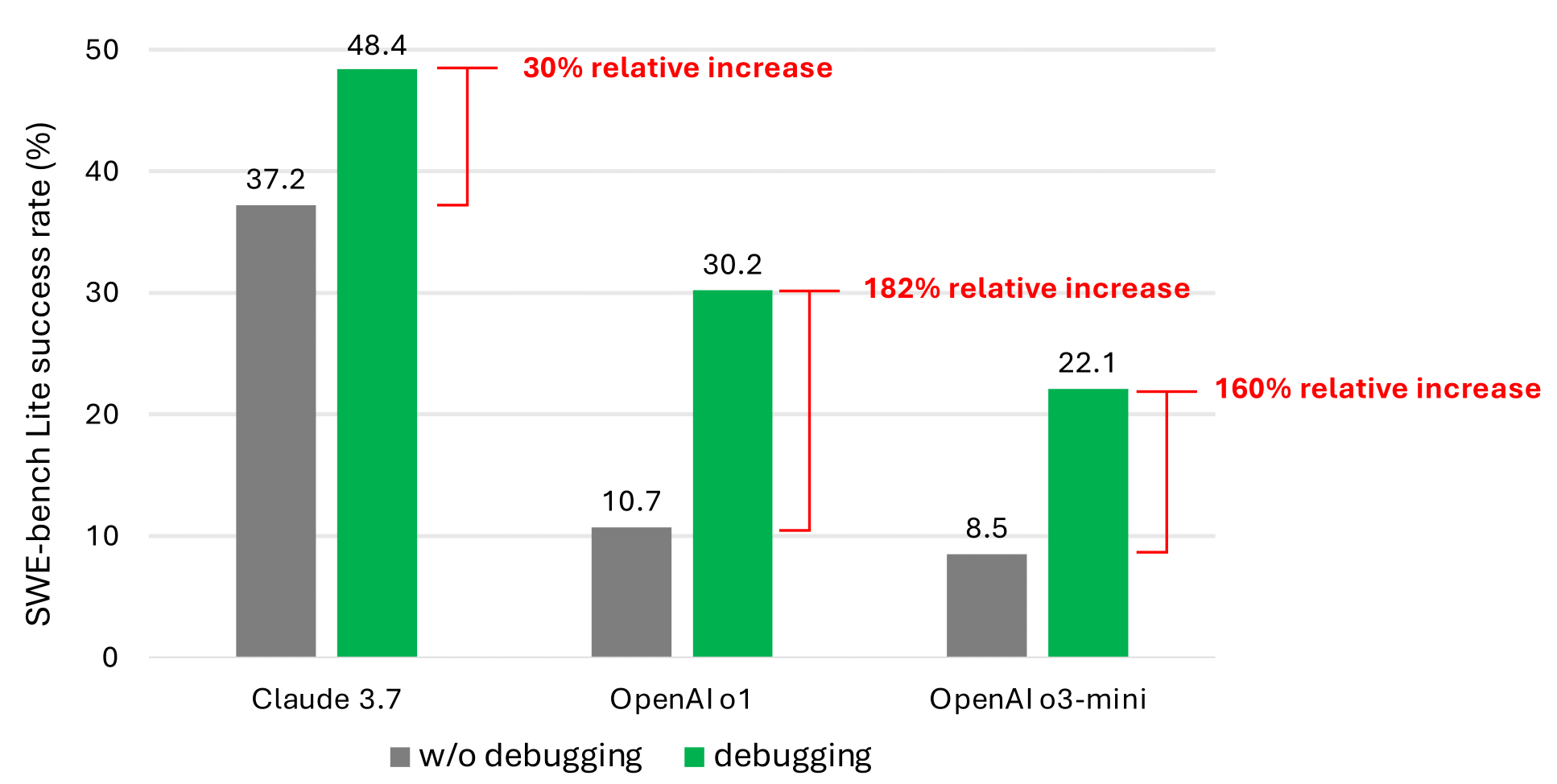
Even with debugging tools, our simple prompt-based agent rarely solves more than half of the SWE-bench (opens in new tab)Lite issues. We believe this is due to the scarcity of data representing sequential decision-making behavior (e.g., debugging traces) in the current LLM training corpus. However, the significant performance improvement (as shown in the most promising results in the graph below) validates that this is a promising research direction.
Microsoft research podcast
What’s Your Story: Lex Story
Model maker and fabricator Lex Story helps bring research to life through prototyping. He discusses his take on failure; the encouragement and advice that has supported his pursuit of art and science; and the sabbatical that might inspire his next career move.
Future work
We believe that training or fine-tuning LLMs can enhance their interactive debugging abilities. This requires specialized data, such as trajectory data that records agents interacting with a debugger to gather information before suggesting a fix. Unlike conventional reasoning problems, interactive debugging involves generating actions at each step that trigger feedback from the environment. This feedback helps the agent make new decisions, requiring dense data like the problem description and the sequence of actions leading to the solution.
Our plan is to fine-tune an info-seeking model specialized in gathering the necessary information to resolve bugs. The goal is to use this model to actively build relevant context for a code generation model. If the code generation model is large, there is an opportunity to build a smaller info-seeking model that can provide relevant information to the larger one, e.g., a generalization of retrieval augmented generation (RAG), thus saving AI inference costs. The data collected during the reinforcement learning loop to train the info-seeking model can also be used to fine-tune larger models for interactive debugging.
We are open-sourcing debug-gym to facilitate this line of research. We encourage the community to help us advance this research towards building interactive debugging agents and, more generally, agents that can seek information by interacting with the world on demand.
Acknowledgements
We thank Ruoyao Wang for their insightful discussion on building interactive debugging agents, Chris Templeman and Elaina Maffeo for their team coaching, Jessica Mastronardi and Rich Ciapala for their kind support in project management and resource allocation, and Peter Jansen for providing valuable feedback for the technical report.