


Today, we’re excited to announce the launch of Amazon SageMaker Large Model Inference (LMI) container v15, powered by vLLM 0.8.4 with support for the vLLM V1 engine. This version now supports the latest open-source models, such as Meta’s Llama 4 models Scout and Maverick, Google’s Gemma 3, Alibaba’s Qwen, Mistral AI, DeepSeek-R, and many more. Amazon SageMaker AI continues to evolve its generative AI inference capabilities to meet the growing demands in performance and model support for foundation models (FMs).
This release introduces significant performance improvements, expanded model compatibility with multimodality (that is, the ability to understand and analyze text-to-text, images-to-text, and text-to-images data), and provides built-in integration with vLLM to help you seamlessly deploy and serve large language models (LLMs) with the highest performance at scale.
What’s new?
LMI v15 brings several enhancements that improve throughput, latency, and usability:
- An async mode that directly integrates with vLLM’s AsyncLLMEngine for improved request handling. This mode creates a more efficient background loop that continuously processes incoming requests, enabling it to handle multiple concurrent requests and stream outputs with higher throughput than the previous Rolling-Batch implementation in v14.
- Support for the vLLM V1 engine, which delivers up to 111% higher throughput compared to the previous V0 engine for smaller models at high concurrency. This performance improvement comes from reduced CPU overhead, optimized execution paths, and more efficient resource utilization in the V1 architecture. LMI v15 supports both V1 and V0 engines, with V1 being the default. If you have a need to use V0, you can use the V0 engine by specifying
VLLM_USE_V1=0. vLLM V1’s engine also comes with a core re-architecture of the serving engine with simplified scheduling, zero-overhead prefix caching, clean tensor-parallel inference, efficient input preparation, and advanced optimizations with torch.compile and Flash Attention 3. For more information, see the vLLM Blog. - Expanded API schema support with three flexible options to allow seamless integration with applications built on popular API patterns:
- Message format compatible with the OpenAI Chat Completions API.
- OpenAI Completions format.
- Text Generation Inference (TGI) schema to support backward compatibility with older models.
- Multimodal support, with enhanced capabilities for vision-language models including optimizations such as multimodal prefix caching
- Built-in support for function calling and tool calling, enabling sophisticated agent-based workflows.
Enhanced model support
LMI v15 supports an expanding roster of state-of-the-art models, including the latest releases from leading model providers. The container offers ready-to-deploy compatibility for but not limited to:
- Llama 4 – Llama-4-Scout-17B-16E and Llama-4-Maverick-17B-128E-Instruct
- Gemma 3 – Google’s lightweight and efficient models, known for their strong performance despite smaller size
- Qwen 2.5 – Alibaba’s advanced models including QwQ 2.5 and Qwen2-VL with multimodal capabilities
- Mistral AI models – High-performance models from Mistral AI that offer efficient scaling and specialized capabilities
- DeepSeek-R1/V3 – State of the art reasoning models
Each model family can be deployed using the LMI v15 container by specifying the appropriate model ID, for example, meta-llama/Llama-4-Scout-17B-16E, and configuration parameters as environment variables, without requiring custom code or optimization work.
Benchmarks
Our benchmarks demonstrate the performance advantages of LMI v15’s V1 engine compared to previous versions:
| Model | Batch size | Instance type | LMI v14 throughput [tokens/s] (V0 engine) | LMI v15 throughput [tokens/s] (V1 engine) | Improvement | |
| 1 | deepseek-ai/DeepSeek-R1-Distill-Llama-70B | 128 | p4d.24xlarge | 1768 | 2198 | 24% |
| 2 | meta-llama/Llama-3.1-8B-Instruct | 64 | ml.g6e.2xlarge | 1548 | 2128 | 37% |
| 3 | mistralai/Mistral-7B-Instruct-v0.3 | 64 | ml.g6e.2xlarge | 942 | 1988 | 111% |
DeepSeek-R1 Llama 70B for various levels of concurrency

Llama 3.1 8B Instruct for various level of concurrency
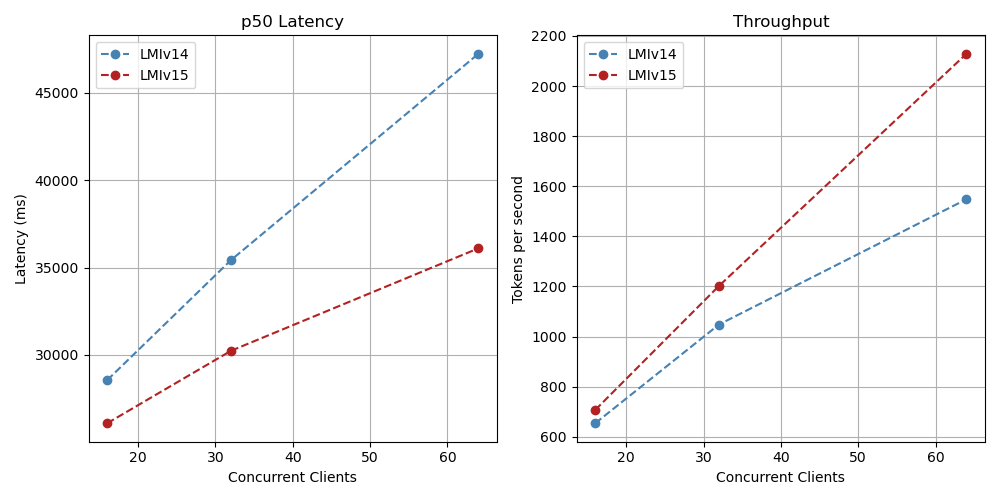
Mistral 7B for various levels of concurrency

The async engine in LMI v15 shows strength in high-concurrency scenarios, where multiple simultaneous requests benefit from the optimized request handling. These benchmarks highlight that the V1 engine in async mode delivers between 24% and 111% higher throughput compared to LMI v14 using rolling batch in the models tested in high concurrency scenarios for batch size of 64 and 128. We suggest to keep in mind the following considerations for optimal performance:
- Higher batch sizes increase concurrency but come with a natural tradeoff in terms of latency
- Batch sizes of 4 and 8 provide the best latency for most use cases
- Batch sizes up to 64 and 128 achieve maximum throughput with acceptable latency trade-offs
API formats
LMI v15 supports three API schemas: OpenAI Chat Completions, OpenAI Completions, and TGI.
- Chat Completions – Message format is compatible with OpenAI Chat Completions API. Use this schema for tool calling, reasoning, and multimodal use cases. Here is a sample of the invocation with the Messages API:
- OpenAI Completions format – The Completions API endpoint is no longer receiving updates:
- TGI – Supports backward compatibility with older models:
Getting started with LMI v15
Getting started with LMI v15 is seamless, and you can deploy with LMI v15 in only a few lines of code. The container is available through Amazon Elastic Container Registry (Amazon ECR), and deployments can be managed through SageMaker AI endpoints. To deploy models, you need to specify the Hugging Face model ID, instance type, and configuration options as environment variables.
For optimal performance, we recommend the following instances:
- Llama 4 Scout: ml.p5.48xlarge
- DeepSeek R1/V3: ml.p5e.48xlarge
- Qwen 2.5 VL-32B: ml.g5.12xlarge
- Qwen QwQ 32B: ml.g5.12xlarge
- Mistral Large: ml.g6e.48xlarge
- Gemma3-27B: ml.g5.12xlarge
- Llama 3.3-70B: ml.p4d.24xlarge
To deploy with LMI v15, follow these steps:
- Clone the notebook to your Amazon SageMaker Studio notebook or to Visual Studio Code (VS Code). You can then run the notebook to do the initial setup and deploy the model from the Hugging Face repository to the SageMaker AI endpoint. We walk through the key blocks here.
- LMI v15 maintains the same configuration pattern as previous versions, using environment variables in the form
OPTION_. This consistent approach makes it straightforward for users familiar with earlier LMI versions to migrate to v15.HF_MODEL_IDsets the model id from Hugging Face. You can also download model from Amazon Simple Storage Service (Amazon S3).HF_TOKENsets the token to download the model. This is required for gated models like Llama-4OPTION_MAX_MODEL_LEN. This is the max model context length.OPTION_MAX_ROLLING_BATCH_SIZEsets the batch size for the model.OPTION_MODEL_LOADING_TIMEOUTsets the timeout value for SageMaker to load the model and run health checks.SERVING_FAIL_FAST=true. We recommend setting this flag because it allows SageMaker to gracefully restart the container when an unrecoverable engine error occurs.OPTION_ROLLING_BATCH= disabledisables the rolling batch implementation of LMI, which was the default offering in LMI V14. We recommend using async instead as this latest implementation and provides better performanceOPTION_ASYNC_MODE=trueenables async mode.OPTION_ENTRYPOINTprovides the entrypoint for vLLM’s async integrations
- Set the latest container (in this example we used
0.33.0-lmi15.0.0-cu128), AWS Region (us-east-1), and create a model artifact with all the configurations. To review the latest available container version, see Available Deep Learning Containers Images. - Deploy the model to the endpoint using
model.deploy(). - Invoke the model, SageMaker inference provides two APIs to invoke the model-
InvokeEndpointandInvokeEndpointWithResponseStream. You can choose either option based on your needs.
To run multi-modal inference with Llama-4 Scout, see the notebook for the full code sample to run inference requests with images.
Conclusion
Amazon SageMaker LMI container v15 represents a significant step forward in large model inference capabilities. With the new vLLM V1 engine, async operating mode, expanded model support, and optimized performance, you can deploy cutting-edge LLMs with greater performance and flexibility. The container’s configurable options give you the flexibility to fine-tune deployments for your specific needs, whether optimizing for latency, throughput, or cost.
We encourage you to explore this release for deploying your generative AI models.
Check out the provided example notebooks to start deploying models with LMI v15.
About the authors
 Vivek Gangasani is a Lead Specialist Solutions Architect for Inference at AWS. He helps emerging generative AI companies build innovative solutions using AWS services and accelerated compute. Currently, he is focused on developing strategies for fine-tuning and optimizing the inference performance of large language models. In his free time, Vivek enjoys hiking, watching movies, and trying different cuisines.
Vivek Gangasani is a Lead Specialist Solutions Architect for Inference at AWS. He helps emerging generative AI companies build innovative solutions using AWS services and accelerated compute. Currently, he is focused on developing strategies for fine-tuning and optimizing the inference performance of large language models. In his free time, Vivek enjoys hiking, watching movies, and trying different cuisines.
 Siddharth Venkatesan is a Software Engineer in AWS Deep Learning. He currently focusses on building solutions for large model inference. Prior to AWS he worked in the Amazon Grocery org building new payment features for customers world-wide. Outside of work, he enjoys skiing, the outdoors, and watching sports.
Siddharth Venkatesan is a Software Engineer in AWS Deep Learning. He currently focusses on building solutions for large model inference. Prior to AWS he worked in the Amazon Grocery org building new payment features for customers world-wide. Outside of work, he enjoys skiing, the outdoors, and watching sports.
 Felipe Lopez is a Senior AI/ML Specialist Solutions Architect at AWS. Prior to joining AWS, Felipe worked with GE Digital and SLB, where he focused on modeling and optimization products for industrial applications.
Felipe Lopez is a Senior AI/ML Specialist Solutions Architect at AWS. Prior to joining AWS, Felipe worked with GE Digital and SLB, where he focused on modeling and optimization products for industrial applications.
 Banu Nagasundaram leads product, engineering, and strategic partnerships for Amazon SageMaker JumpStart, the SageMaker machine learning and generative AI hub. She is passionate about building solutions that help customers accelerate their AI journey and unlock business value.
Banu Nagasundaram leads product, engineering, and strategic partnerships for Amazon SageMaker JumpStart, the SageMaker machine learning and generative AI hub. She is passionate about building solutions that help customers accelerate their AI journey and unlock business value.
 Dmitry Soldatkin is a Senior AI/ML Solutions Architect at Amazon Web Services (AWS), helping customers design and build AI/ML solutions. Dmitry’s work covers a wide range of ML use cases, with a primary interest in Generative AI, deep learning, and scaling ML across the enterprise. He has helped companies in many industries, including insurance, financial services, utilities, and telecommunications. You can connect with Dmitry on LinkedIn.
Dmitry Soldatkin is a Senior AI/ML Solutions Architect at Amazon Web Services (AWS), helping customers design and build AI/ML solutions. Dmitry’s work covers a wide range of ML use cases, with a primary interest in Generative AI, deep learning, and scaling ML across the enterprise. He has helped companies in many industries, including insurance, financial services, utilities, and telecommunications. You can connect with Dmitry on LinkedIn.