


Amazon Bedrock offers model customization capabilities for customers to tailor versions of foundation models (FMs) to their specific needs through features such as fine-tuning and distillation. Today, we’re announcing the launch of on-demand deployment for customized models ready to be deployed on Amazon Bedrock.
On-demand deployment for customized models provides an additional deployment option that scales with your usage patterns. This approach allows for invoking customized models only when needed, with requests processed in real time without requiring pre-provisioned compute resources.
The on-demand deployment option includes a token-based pricing model that charges based on the number of tokens processed during inference. This pay-as-you-go approach complements the existing Provisioned Throughput option, giving users flexibility to choose the deployment method that best aligns with their specific workload requirements and cost objectives.
In this post, we walk through the custom model on-demand deployment workflow for Amazon Bedrock and provide step-by-step implementation guides using both the AWS Management Console and APIs or AWS SDKs. We also discuss best practices and considerations for deploying customized Amazon Nova models on Amazon Bedrock.
Understanding custom model on-demand deployment workflow
The model customization lifecycle represents the end-to-end journey from conceptualization to deployment. This process begins with defining your specific use case, preparing and formatting appropriate data, and then performing model customization through features such as Amazon Bedrock fine-tuning or Amazon Bedrock Model Distillation. Each stage builds upon the previous one, creating a pathway toward deploying production-ready generative AI capabilities that you tailor to your requirements. The following diagram illustrates this workflow.
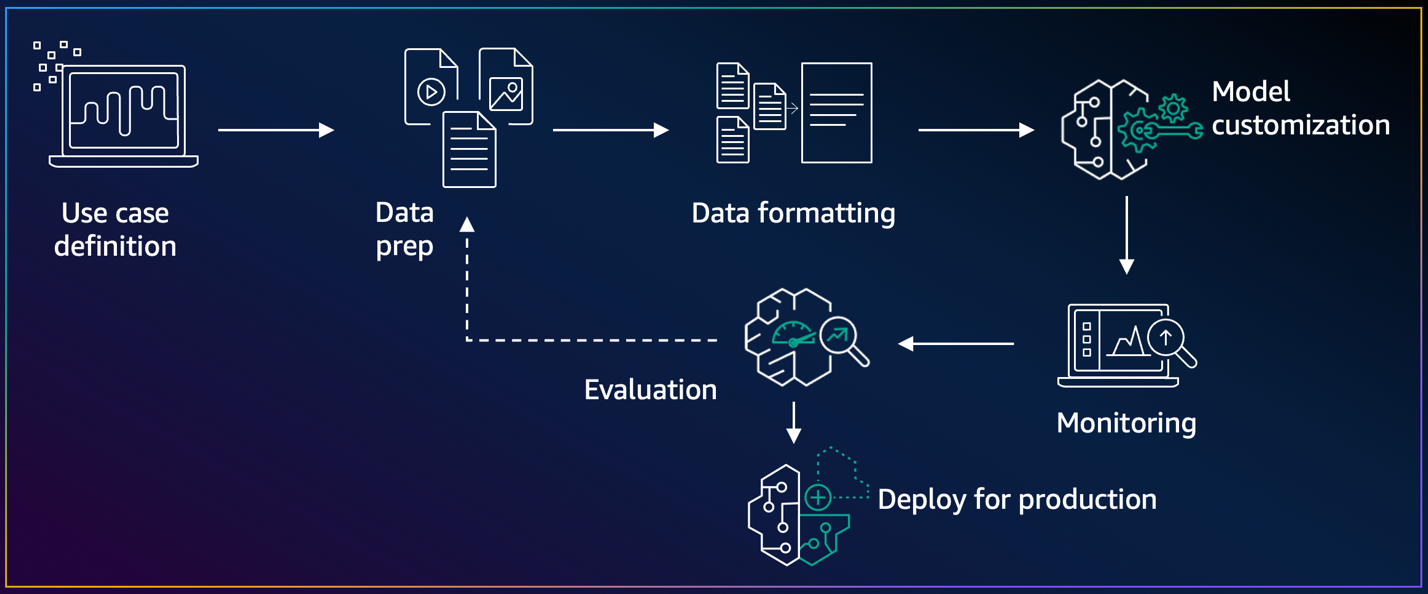
After customizing your model, the evaluation and deployment phases determine how the model will be made available for inference. This is where custom model on-demand deployment becomes valuable, offering a deployment option that aligns with variable workloads and cost-conscious implementations. When using on-demand deployment, you can invoke your customized model through the AWS console or standard API operations using the model identifier, with compute resources automatically allocated only when needed. The on-demand deployment provides flexibility while maintaining performance expectations, so you can seamlessly integrate customized models into your applications with the same serverless experience offered by Amazon Bedrock—all compute resources are automatically managed for you, based on your actual usage. Because the workflow supports iterative improvements, you can refine your models based on evaluation results and evolving business needs.
Prerequisites
This post assumes you have a customized Amazon Nova model before deploying it using on-demand deployment. On-demand deployment requires newly customized Amazon Nova models after this launch. Previously customized models aren’t compatible with this deployment option. For instructions on creating or customizing your Nova model through fine-tuning or distillation, refer to these resources:
After you’ve successfully customized your Amazon Nova model, you can proceed with deploying it using the on-demand deployment option as detailed in the following sections.
Implementation guide for on-demand deployment
There are two main approaches to implementing on-demand deployment for your customized Amazon Nova models on Amazon Bedrock: using the Amazon Bedrock console or using the API or SDK. First, we explore how to deploy your model through the Amazon Bedrock console, which provides a user-friendly interface for setting up and managing your deployments.
Step-by-step implementation using the Amazon Bedrock console
To implement on-demand deployment for your customized Amazon Nova models on Amazon Bedrock using the console, follow these steps:
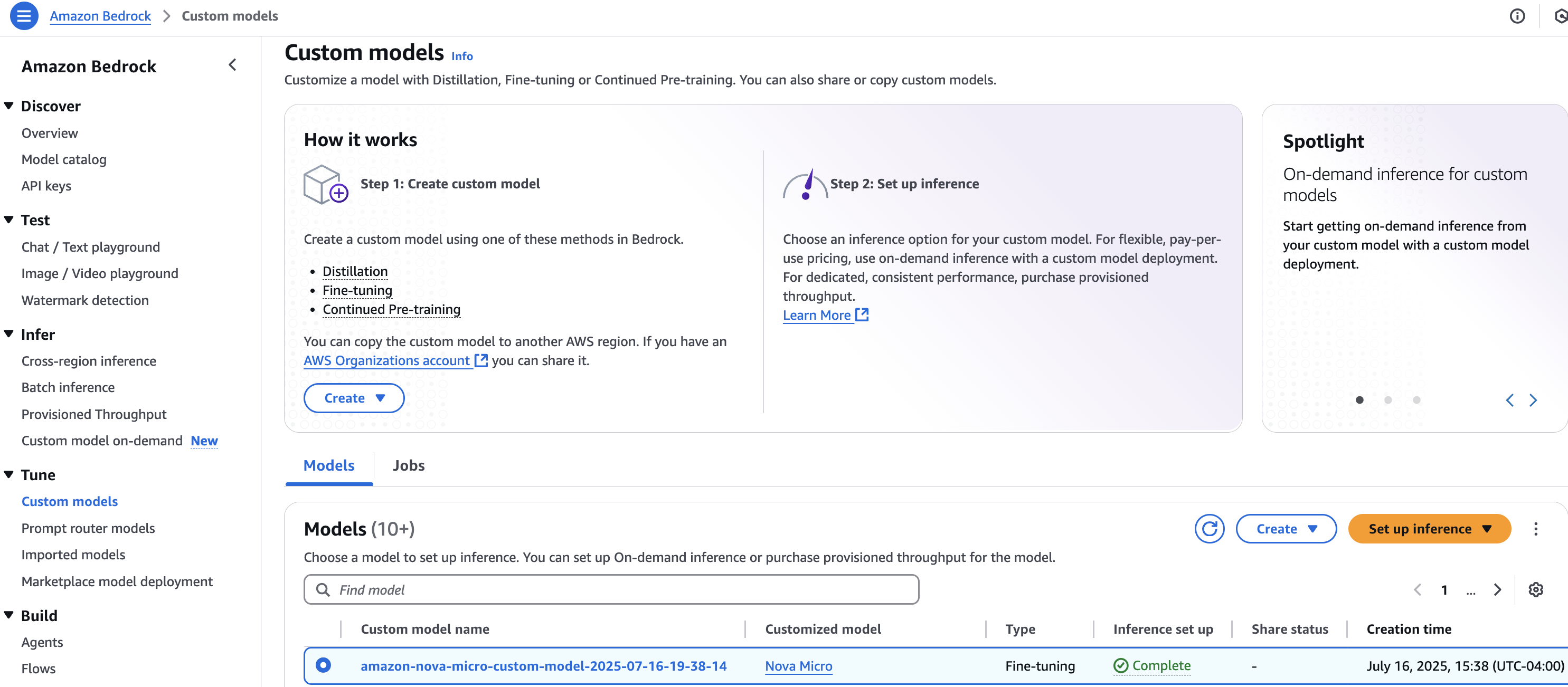
- On the Amazon Bedrock console, select your customized model (fine-tuning or model distillation) to be deployed. Choose Set up inference and select Deploy for on-demand, as shown in the following screenshot.
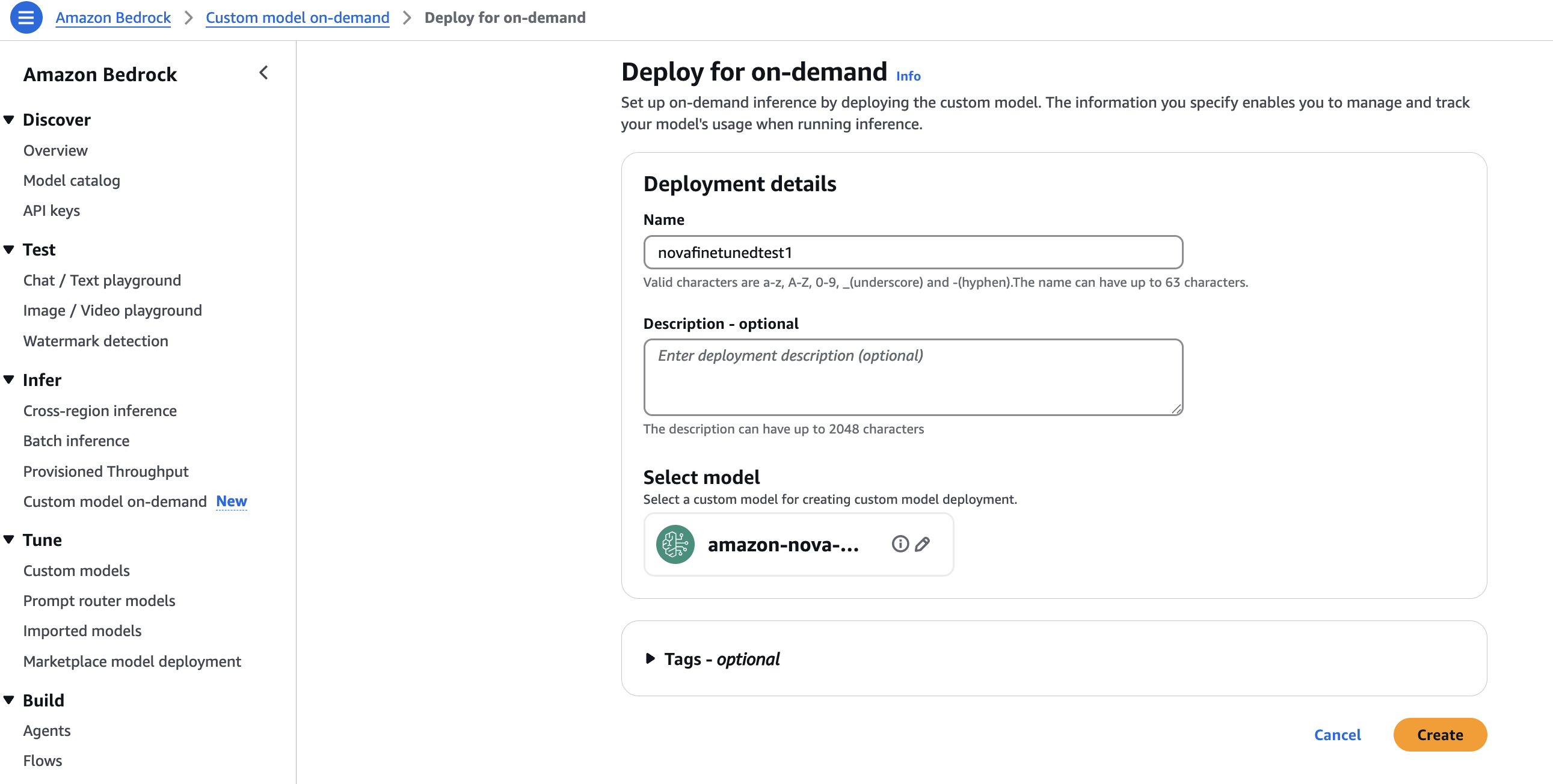
- Under Deployment details, enter a Name and a Description. You have the option to add Tags, as shown in the following screenshot. Choose Create to start on-demand deployment of customized model.
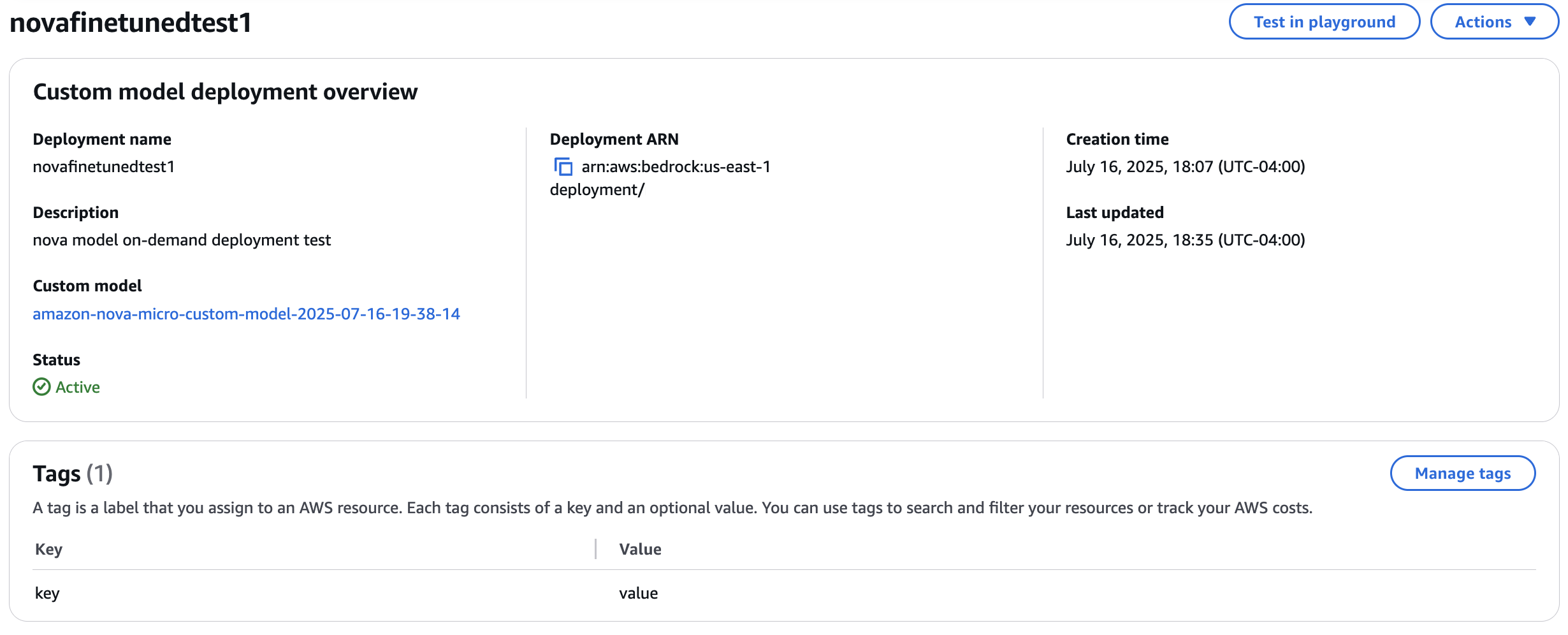
Under Custom model deployments, the status of your deployment should be InProgress, Active, or Failed, as shown in the following screenshot.
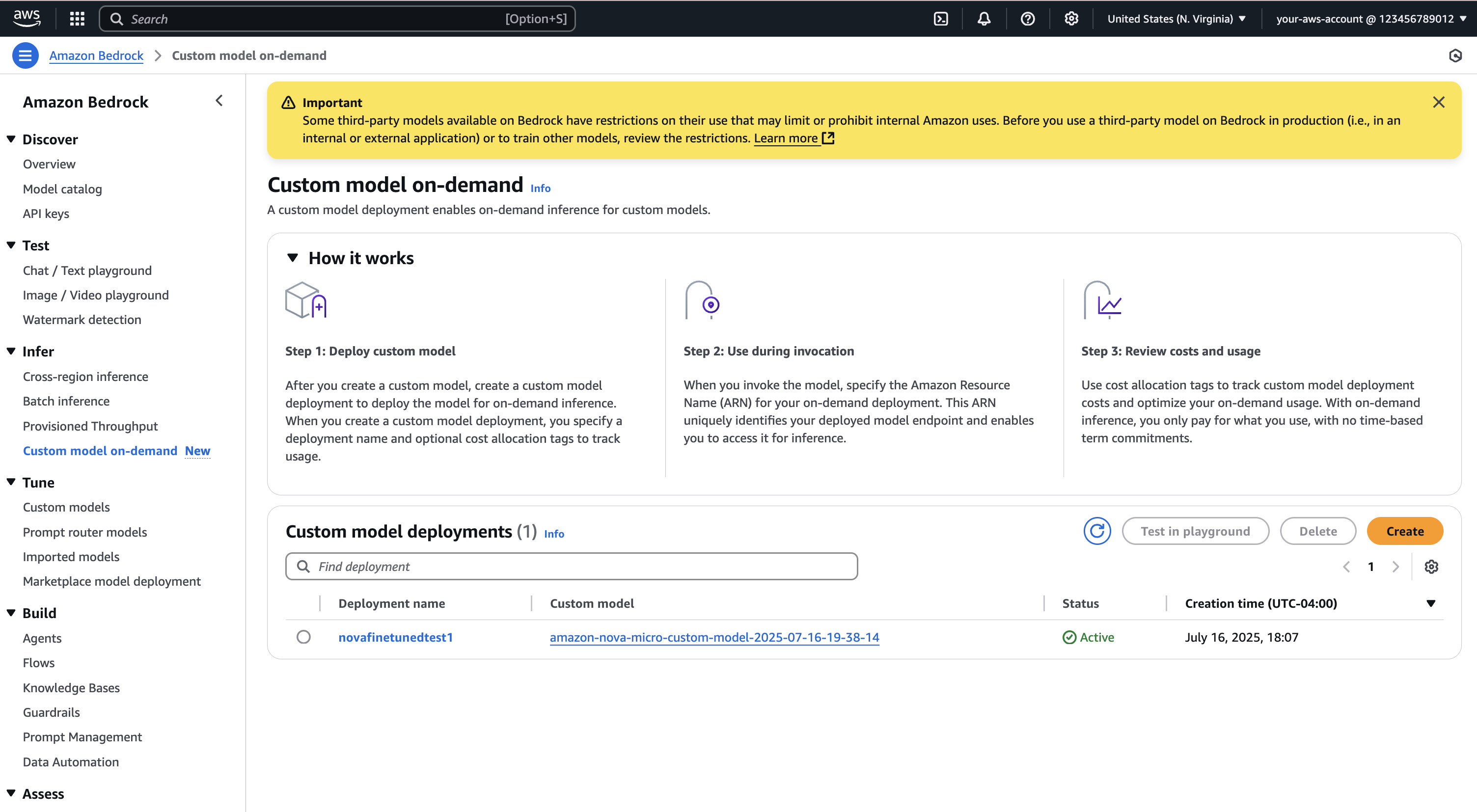
You can select a deployment to find Deployment ARN, Creation time, Last updated, and Status for the selected custom model.
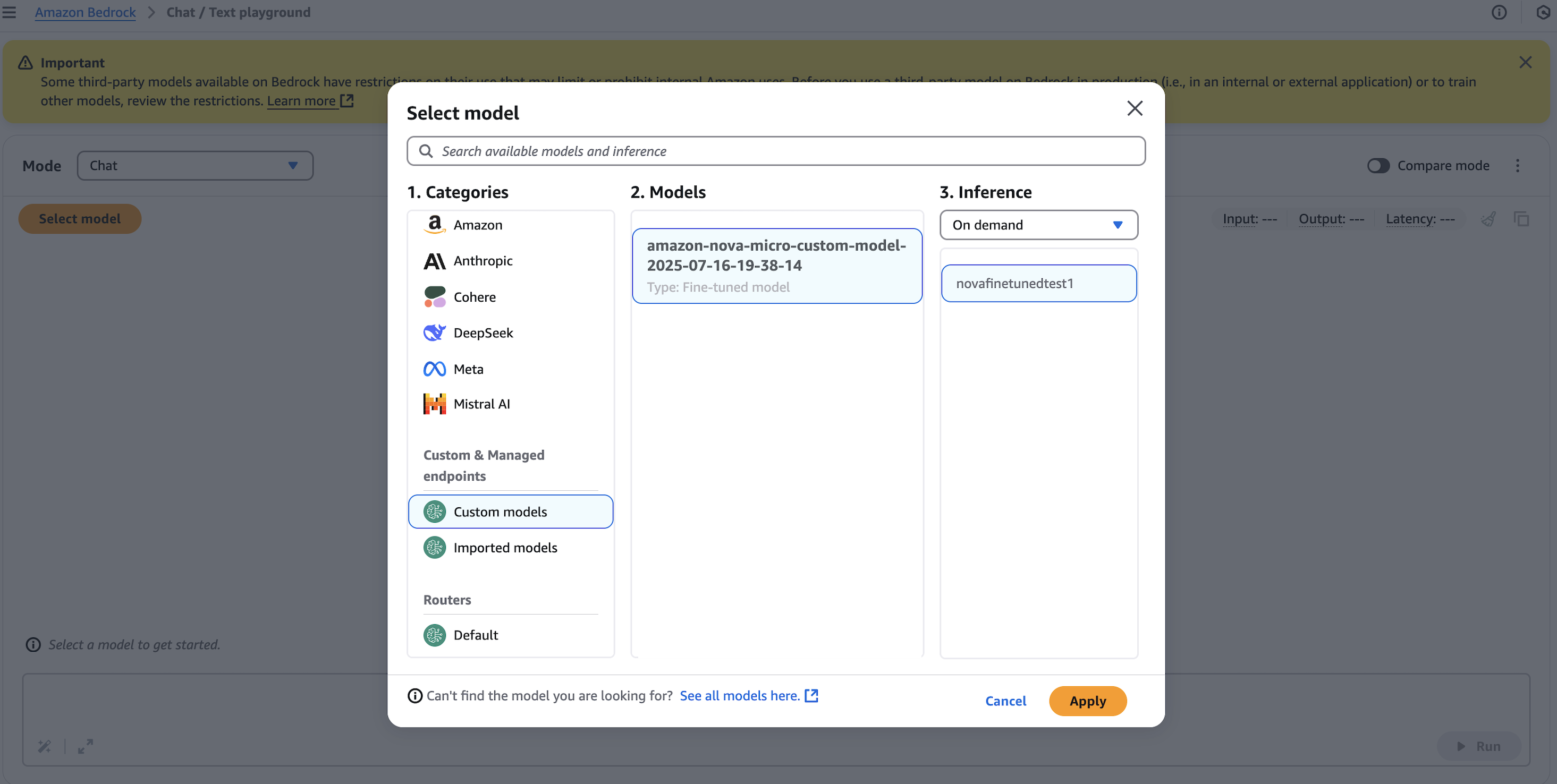
The custom model is deployed and ready using on-demand deployment. Try it out in the test playground or go to Chat/Text playground, choose Custom models under Categories. Select your model, choose On demand under Inference, and select by the deployment name, as shown in the following screenshot.
Step-by-step implementation using API or SDK
After you have trained the model successfully, you can deploy it to evaluate the response quality and latency or to use the model as a production model for your use case. You use CreateCustomModelDeployment API to create model deployment for the trained model. The following steps show how to use the APIs for deploying and deleting the custom model deployment for on-demand inference.
After you’ve successfully created a model deployment, you can check the status of the deployment by using GetCustomModelDeployment API as follows:
GetCustomModelDeployment supports three states: Creating , Active , and Failed. When the status in response is Active, you should be able to use the custom model through on-demand deployment with InvokeModel or Converse API, as shown in the following example:
By following these steps, you can deploy and use your customized model through Amazon Bedrock API and instantly use your efficient and high-performing model tailored to your use cases through on-demand deployment.
Best practices and considerations
Successful implementation of on-demand deployment with customized models depends on understanding several operational factors. These considerations—including latency, Regional availability, quota limitations, deployment option selections, and cost management strategies—directly impact your ability to deploy effective solutions while optimizing resource utilization. The following guidelines help you make informed decisions when implementing your inference strategy:
- Cold start latency – When using on-demand deployment, you might experience initial cold start latencies, typically lasting several seconds, depending on the model size. This occurs when the deployment hasn’t received recent traffic and needs to reinitialize compute resources.
- Regional availability – At launch, custom model deployment will be available in US East (N. Virginia) for Amazon Nova models.
- Quota management – Each custom model deployment has specific quotas:
- Tokens per minute (TPM)
- Requests per minute (RPM)
- The number of
Creatingstatus deployment - Total on-demand deployments in a single account
Each deployment operates independently within its assigned quota. If a deployment exceeds its TPM or RPM allocation, incoming requests will be throttled. You can request quota increases by submitting a ticket or contacting your AWS account team.
- Choosing between custom model deployment and Provisioned Throughput – You can set up inference on a custom model by either creating a custom model deployment (for on-demand usage) or purchasing Provisioned Throughput. The choice depends on the supported Regions and models for each inference option, throughput requirement, and cost considerations. These two options operate independently and can be used simultaneously for the same custom model.
- Cost management – On-demand deployment uses a pay-as-you-go pricing model based on the number of tokens processed during inference. You can use cost allocation tags on your on-demand deployments to track and manage inference costs, allowing better budget tracking and cost optimization through AWS Cost Explorer.
Cleanup
If you’ve been testing the on-demand deployment feature and don’t plan to continue using it, it’s important to clean up your resources to avoid incurring unnecessary costs. Here’s how to delete using the Amazon Bedrock Console:
- Navigate to your custom model deployment
- Select the deployment you want to remove
- Delete the deployment
Here’s how to delete using the API or SDK:
To delete a custom model deployment, you can use DeleteCustomModelDeployment API. The following example demonstrates how to delete your custom model deployment:
Conclusion
The introduction of on-demand deployment for customized models on Amazon Bedrock represents a significant advancement in making AI model deployment more accessible, cost-effective, and flexible for businesses of all sizes. On-demand deployment offers the following advantages:
- Cost optimization – Pay-as-you-go pricing allows you only pay for the compute resources you actually use
- Operational simplicity – Automatic resource management eliminates the need for manual infrastructure provisioning
- Scalability – Seamless handling of variable workloads without upfront capacity planning
- Flexibility – Freedom to choose between on-demand and Provisioned Throughput based on your specific needs
Getting started is straightforward. Begin by completing your model customization through fine-tuning or distillation, then choose on-demand deployment using the AWS Management Console or API. Configure your deployment details, validate model performance in a test environment, and seamlessly integrate into your production workflows.
Start exploring on-demand deployment for customized models on Amazon Bedrock today! Visit the Amazon Bedrock documentation to begin your model customization journey and experience the benefits of flexible, cost-effective AI infrastructure. For hands-on implementation examples, check out our GitHub repository which contains detailed code samples for customizing Amazon Nova models and evaluating them using on-demand custom model deployment.
About the Authors
 Yanyan Zhang is a Senior Generative AI Data Scientist at Amazon Web Services, where she has been working on cutting-edge AI/ML technologies as a Generative AI Specialist, helping customers use generative AI to achieve their desired outcomes. Yanyan graduated from Texas A&M University with a PhD in Electrical Engineering. Outside of work, she loves traveling, working out, and exploring new things.
Yanyan Zhang is a Senior Generative AI Data Scientist at Amazon Web Services, where she has been working on cutting-edge AI/ML technologies as a Generative AI Specialist, helping customers use generative AI to achieve their desired outcomes. Yanyan graduated from Texas A&M University with a PhD in Electrical Engineering. Outside of work, she loves traveling, working out, and exploring new things.
 Sovik Kumar Nath is an AI/ML and Generative AI senior solution architect with AWS. He has extensive experience designing end-to-end machine learning and business analytics solutions in finance, operations, marketing, healthcare, supply chain management, and IoT. He has double masters degrees from the University of South Florida, University of Fribourg, Switzerland, and a bachelors degree from the Indian Institute of Technology, Kharagpur. Outside of work, Sovik enjoys traveling, taking ferry rides, and watching movies.
Sovik Kumar Nath is an AI/ML and Generative AI senior solution architect with AWS. He has extensive experience designing end-to-end machine learning and business analytics solutions in finance, operations, marketing, healthcare, supply chain management, and IoT. He has double masters degrees from the University of South Florida, University of Fribourg, Switzerland, and a bachelors degree from the Indian Institute of Technology, Kharagpur. Outside of work, Sovik enjoys traveling, taking ferry rides, and watching movies.
 Ishan Singh is a Sr. Generative AI Data Scientist at Amazon Web Services, where he helps customers build innovative and responsible generative AI solutions and products. With a strong background in AI/ML, Ishan specializes in building generative AI solutions that drive business value. Outside of work, he enjoys playing volleyball, exploring local bike trails, and spending time with his wife and dog, Beau.
Ishan Singh is a Sr. Generative AI Data Scientist at Amazon Web Services, where he helps customers build innovative and responsible generative AI solutions and products. With a strong background in AI/ML, Ishan specializes in building generative AI solutions that drive business value. Outside of work, he enjoys playing volleyball, exploring local bike trails, and spending time with his wife and dog, Beau.
 Koushik Mani is an associate solutions architect at AWS. He had worked as a Software Engineer for two years focusing on machine learning and cloud computing use cases at Telstra. He completed his masters in computer science from University of Southern California. He is passionate about machine learning and generative AI use cases and building solutions.
Koushik Mani is an associate solutions architect at AWS. He had worked as a Software Engineer for two years focusing on machine learning and cloud computing use cases at Telstra. He completed his masters in computer science from University of Southern California. He is passionate about machine learning and generative AI use cases and building solutions.
 Rishabh Agrawal is a Senior Software Engineer working on AI services at AWS. In his spare time, he enjoys hiking, traveling and reading.
Rishabh Agrawal is a Senior Software Engineer working on AI services at AWS. In his spare time, he enjoys hiking, traveling and reading.
 Shreeya Sharma is a Senior Technical Product Manager at AWS, where she has been working on leveraging the power of generative AI to deliver innovative and customer-centric products. Shreeya holds a master’s degree from Duke University. Outside of work, she loves traveling, dancing, and singing.
Shreeya Sharma is a Senior Technical Product Manager at AWS, where she has been working on leveraging the power of generative AI to deliver innovative and customer-centric products. Shreeya holds a master’s degree from Duke University. Outside of work, she loves traveling, dancing, and singing.