








Today, we’re excited to announce that Amazon SageMaker HyperPod now supports managed node automatic scaling with Karpenter, so you can efficiently scale your SageMaker HyperPod clusters to meet your inference and training demands. Real-time inference workloads require automatic scaling to address unpredictable traffic patterns and maintain service level agreements (SLAs). As demand spikes, organizations must rapidly adapt their GPU compute without compromising response times or cost-efficiency. Unlike self-managed Karpenter deployments, this service-managed solution alleviates the operational overhead of installing, configuring, and maintaining Karpenter controllers, while providing tighter integration with the resilience capabilities of SageMaker HyperPod. This managed approach supports scale to zero, reducing the need for dedicated compute resources to run the Karpenter controller itself, improving cost-efficiency.
SageMaker HyperPod offers a resilient, high-performance infrastructure, observability, and tooling optimized for large-scale model training and deployment. Companies like Perplexity, HippocraticAI, H.AI, and Articul8 are already using SageMaker HyperPod for training and deploying models. As more customers transition from training foundation models (FMs) to running inference at scale, they require the ability to automatically scale their GPU nodes to handle real production traffic by scaling up during high demand and scaling down during periods of lower utilization. This capability necessitates a powerful cluster auto scaler. Karpenter, an open source Kubernetes node lifecycle manager created by AWS, is a popular choice among Kubernetes users for cluster auto scaling due to its powerful capabilities that optimize scaling times and reduce costs.
This launch provides a managed Karpenter-based solution for automatic scaling that is installed and maintained by SageMaker HyperPod, removing the undifferentiated heavy lifting of setup and management from customers. The feature is available for SageMaker HyperPod EKS clusters, and you can enable auto scaling to transform your SageMaker HyperPod cluster from static capacity to a dynamic, cost-optimized infrastructure that scales with demand. This combines Karpenter’s proven node lifecycle management with the purpose-built and resilient infrastructure of SageMaker HyperPod, designed for large-scale machine learning (ML) workloads. In this post, we dive into the benefits of Karpenter, and provide details on enabling and configuring Karpenter in your SageMaker HyperPod EKS clusters.
New features and benefits
Karpenter-based auto scaling in your SageMaker HyperPod clusters provides the following capabilities:
- Service managed lifecycle – SageMaker HyperPod handles Karpenter installation, updates, and maintenance, alleviating operational overhead
- Just-in-time provisioning – Karpenter observes your pending pods and provisions the required compute for your workloads from an on-demand pool
- Scale to zero – You can scale down to zero nodes without maintaining dedicated controller infrastructure
- Workload-aware node selection – Karpenter chooses optimal instance types based on pod requirements, Availability Zones, and pricing to minimize costs
- Automatic node consolidation – Karpenter regularly evaluates clusters for optimization opportunities, shifting workloads to avoid underutilized nodes
- Integrated resilience – Karpenter uses the built-in fault tolerance and node recovery mechanisms of SageMaker HyperPod
These capabilities are built on top of recently launched continuous provisioning capabilities, which enables SageMaker HyperPod to automatically provision remaining capacity in the background while workloads start immediately on available instances. When node provisioning encounters failures due to capacity constraints or other issues, SageMaker HyperPod automatically retries in the background until clusters reach their desired scale, so your auto scaling operations remain resilient and non-blocking.
Solution overview
The following diagram illustrates the solution architecture.
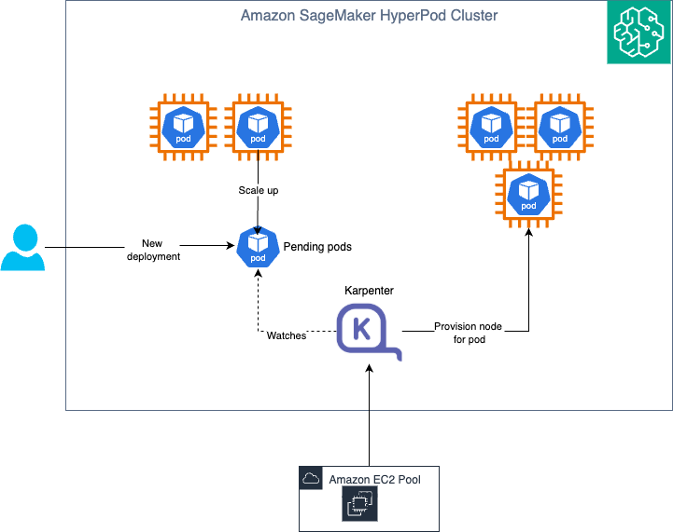

Karpenter works as a controller in the cluster and operates in the following steps:
- Watching – Karpenter watches for un-schedulable pods in the cluster through the Kubernetes API server. These could be pods that go into pending state when deployed or automatically scaled to increase the replica count.
- Evaluating – When Karpenter finds such pods, it computes the shape and size of a NodeClaim to fit the set of pods requirements (GPU, CPU, memory) and topology constraints, and checks if it can pair them with an existing NodePool. For each NodePool, it queries the SageMaker HyperPod APIs to get the instance types supported by the NodePool. It uses the information about instance type metadata (hardware requirements, zone, capacity type) to find a matching NodePool.
- Provisioning – If Karpenter finds a matching NodePool, it creates a NodeClaim and tries to provision a new instance to be used as the new node. Karpenter internally uses the
sagemaker:UpdateClusterAPI to increase the capacity of the selected instance group. - Disrupting – Karpenter periodically checks if a new node is needed or not. If it’s not needed, Karpenter deletes it, which internally translates to a delete node request to the SageMaker HyperPod cluster.
Prerequisites
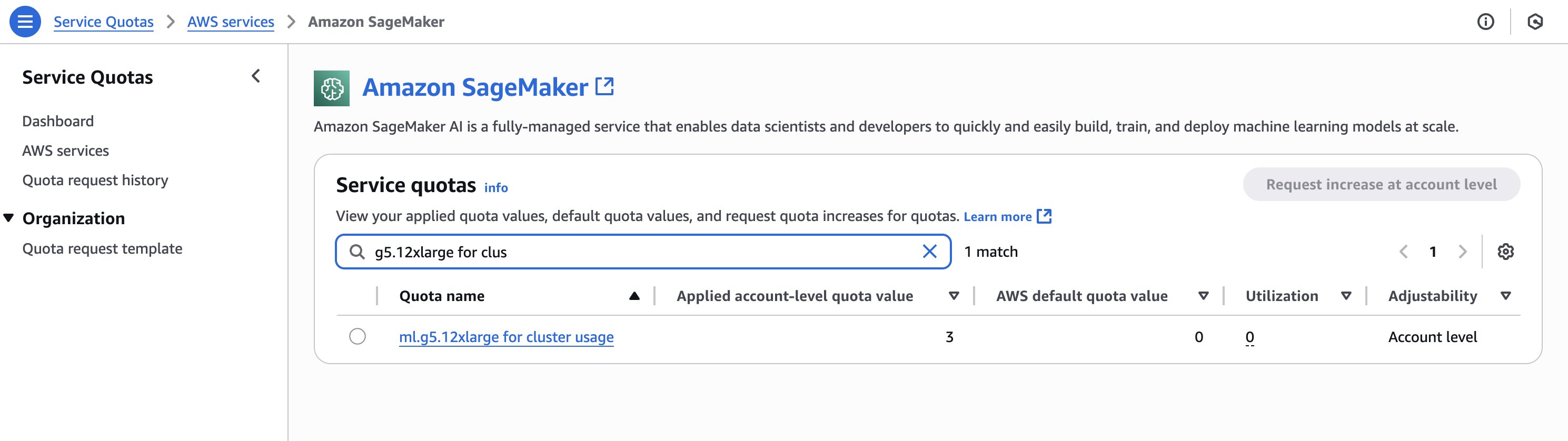
Verify you have the required quotas for the instances you will create in the SageMaker HyperPod cluster. To review your quotas, on the Service Quotas console, choose AWS services in the navigation pane, then choose SageMaker. For example, the following screenshot shows the available quota for g5.12xlarge instances (three).

To update the cluster, you must first create AWS Identity and Access Management (IAM) permissions for Karpenter. For instructions, see Create an IAM role for HyperPod autoscaling with Karpenter.
Create and configure a SageMaker HyperPod cluster
To begin, launch and configure your SageMaker HyperPod EKS cluster and verify that continuous provisioning mode is enabled on cluster creation. Complete the following steps:
- On the SageMaker AI console, choose HyperPod clusters in the navigation pane.
- Choose Create HyperPod cluster and Orchestrated on Amazon EKS.
- For Setup options, select Custom setup.
- For Name, enter a name.
- For Instance recovery, select Automatic.
- For Instance provisioning mode, select Use continuous provisioning.
- Choose Submit.
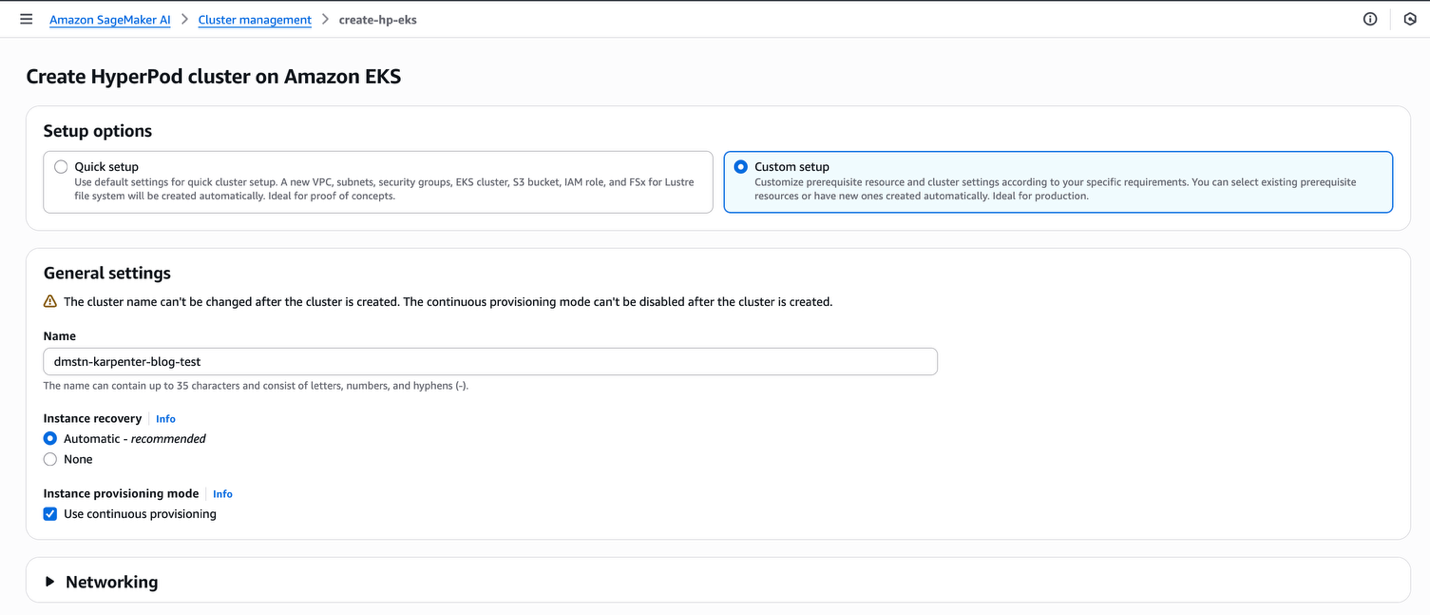

This setup creates the necessary configuration such as virtual private cloud (VPC), subnets, security groups, and EKS cluster, and installs operators in the cluster. You can also provide existing resources such as an EKS cluster if you want to use an existing cluster instead of creating a new one. This setup will take around 20 minutes.
Verify that each InstanceGroup is limited to one zone by opting for the OverrideVpcConfig and selecting only one subnet per each InstanceGroup.


After you create the cluster, you must update it to enable Karpenter. You can do this using Boto3 or the AWS Command Line Interface (AWS CLI) using the UpdateCluster API command (after configuring the AWS CLI to connect to your AWS account).
The following code uses Python Boto3:
After you run this command and update the cluster, you can verify that Karpenter has been enabled by running the DescribeCluster API.
The following code uses Python:
The following code uses the AWS CLI:
The following code shows our output:
Now you have a working cluster. The next step is to set up some custom resources in your cluster for Karpenter.
Create HyperpodNodeClass
HyperpodNodeClass is a custom resource that maps to pre-created instance groups in SageMaker HyperPod, defining constraints around which instance types and Availability Zones are supported for Karpenter’s auto scaling decisions. To use HyperpodNodeClass, simply specify the names of the InstanceGroups of your SageMaker HyperPod cluster that you want to use as the source for the AWS compute resources to use to scale up your pods in your NodePools.
The HyperpodNodeClass name that you use here is carried over to the NodePool in the next section where you reference it. This tells the NodePool which HyperpodNodeClass to draw resources from. To create a HyperpodNodeClass, complete the following steps:
- Create a YAML file (for example,
nodeclass.yaml) similar to the following code. AddInstanceGroupnames that you used at the time of the SageMaker HyperPod cluster creation. You can also add new instance groups to an existing SageMaker HyperPod EKS cluster. - Reference the
HyperPodNodeClassname in your NodePool configuration.
The following is a sample HyperpodNodeClass that uses ml.g6.xlarge and ml.g6.4xlarge instance types:
- Apply the configuration to your EKS cluster using
kubectl:
- Monitor the
HyperpodNodeClassstatus to verify theReadycondition in status is set toTrueto ensure it was successfully created:
The SageMaker HyperPod cluster must have AutoScaling enabled and the AutoScaling status must change to InService before the HyperpodNodeClass can be applied.
For more information and key considerations, see Autoscaling on SageMaker HyperPod EKS.
Create NodePool
The NodePool sets constraints on the nodes that can be created by Karpenter and the pods that can run on those nodes. The NodePool can be set to perform various actions, such as:
- Define labels and taints to limit the pods that can run on nodes Karpenter creates
- Limit node creation to certain zones, instance types, and computer architectures, and so on
For more information about NodePool, refer to NodePools. SageMaker HyperPod managed Karpenter supports a limited set of well-known Kubernetes and Karpenter requirements, which we explain in this post.
To create a NodePool, complete the following steps:
- Create a YAML file named
nodepool.yamlwith your desired NodePool configuration.
The following code is a sample configuration to create a sample NodePool. We specify the NodePool to include our ml.g6.xlarge SageMaker instance type, and we additionally specify it for one zone. Refer to NodePools for more customizations.
- Apply the NodePool to your cluster:
- Monitor the NodePool status to ensure the
Readycondition in the status is set toTrue:
This example shows how a NodePool can be used to specify the hardware (instance type) and placement (Availability Zone) for pods.
Launch a simple workload
The following workload runs a Kubernetes deployment where the pods in deployment are requesting for 1 CPU and 256 MB memory per replica, per pod. The pods have not been spun up yet.
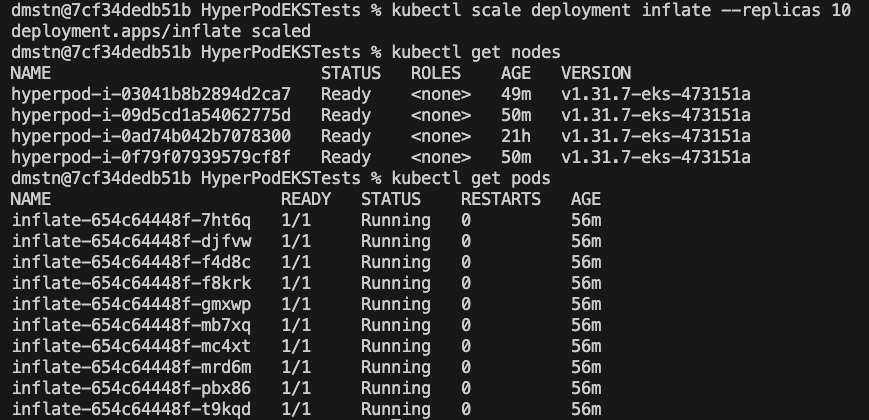
When we apply this, we can see a deployment and a single node launch in our cluster, as shown in the following screenshot.


To scale this component, use the following command:
Within a few minutes, we can see Karpenter add the requested nodes to the cluster.

Implement advanced auto scaling for inference with KEDA and Karpenter
To implement an end-to-end auto scaling solution on SageMaker HyperPod, you can set up Kubernetes Event-driven Autoscaling (KEDA) along with Karpenter. KEDA enables pod-level auto scaling based on a wide range of metrics, including Amazon CloudWatch metrics, Amazon Simple Queue Service (Amazon SQS) queue lengths, Prometheus queries, and resource utilization patterns. By configuring Keda ScaledObject resources to target your model deployments, KEDA can dynamically adjust the number of inference pods based on real-time demand signals.
When integrating KEDA and Karpenter, this combination creates a powerful two-tier auto scaling architecture. As KEDA scales your pods up or down based on workload metrics, Karpenter automatically provisions or deletes nodes in response to changing resource requirements. This integration delivers optimal performance while controlling costs by making sure your cluster has precisely the right amount of compute resources available at all times. For effective implementation, consider the following key factors:
- Set appropriate buffer thresholds in KEDA to accommodate Karpenter’s node provisioning time
- Configure cooldown periods carefully to prevent scaling oscillations
- Define clear resource requests and limits to help Karpenter make optimal node selections
- Create specialized NodePools tailored to specific workload characteristics
The following is a sample spec of a KEDA ScaledObject file that scales the number of pods based on CloudWatch metrics of Application Load Balancer (ALB) request count:
Clean up
To clean up your resources to avoid incurring more charges, delete your SageMaker HyperPod cluster.
Conclusion
With the launch of Karpenter node auto scaling on SageMaker HyperPod, ML workloads can automatically adapt to changing workload requirements, optimize resource utilization, and help control costs by scaling precisely when needed. You can also integrate it with event-driven pod auto scalers such as KEDA to scale based on custom metrics.
To experience these benefits for your ML workloads, enable Karpenter in your SageMaker HyperPod clusters. For detailed implementation guidance and best practices, refer to Autoscaling on SageMaker HyperPod EKS.
About the authors














