


In collaboration with OpenAI, NVIDIA has optimized the company’s new open-source gpt-oss models for NVIDIA GPUs, delivering smart, fast inference from the cloud to the PC. These new reasoning models enable agentic AI applications such as web search, in-depth research and many more.
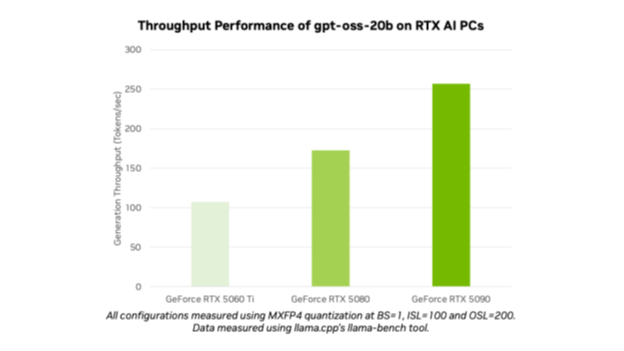
With the launch of gpt-oss-20b and gpt-oss-120b, OpenAI has opened cutting-edge models to millions of users. AI enthusiasts and developers can use the optimized models on NVIDIA RTX AI PCs and workstations through popular tools and frameworks like Ollama, llama.cpp and Microsoft AI Foundry Local, and expect performance of up to 256 tokens per second on the NVIDIA GeForce RTX 5090 GPU.
“OpenAI showed the world what could be built on NVIDIA AI — and now they’re advancing innovation in open-source software,” said Jensen Huang, founder and CEO of NVIDIA. “The gpt-oss models let developers everywhere build on that state-of-the-art open-source foundation, strengthening U.S. technology leadership in AI — all on the world’s largest AI compute infrastructure.”
The models’ release highlights NVIDIA’s AI leadership from training to inference and from cloud to AI PC.
Open for All
Both gpt-oss-20b and gpt-oss-120b are flexible, open-weight reasoning models with chain-of-thought capabilities and adjustable reasoning effort levels using the popular mixture-of-experts architecture. The models are designed to support features like instruction-following and tool use, and were trained on NVIDIA H100 GPUs.
These models can support up to 131,072 context lengths, among the longest available in local inference. This means the models can reason through context problems, ideal for tasks such as web search, coding assistance, document comprehension and in-depth research.
The OpenAI open models are the first MXFP4 models supported on NVIDIA RTX. MXFP4 allows for high model quality, offering fast, efficient performance while requiring fewer resources compared with other precision types.
Run the OpenAI Models on NVIDIA RTX With Ollama
The easiest way to test these models on RTX AI PCs, on GPUs with at least 24GB of VRAM, is using the new Ollama app. Ollama is popular with AI enthusiasts and developers for its ease of integration, and the new user interface (UI) includes out-of-the-box support for OpenAI’s open-weight models. Ollama is fully optimized for RTX, making it ideal for consumers looking to experience the power of personal AI on their PC or workstation.
Once installed, Ollama enables quick, easy chatting with the models. Simply select the model from the dropdown menu and send a message. Because Ollama is optimized for RTX, there are no additional configurations or commands required to ensure top performance on supported GPUs.

Ollama’s new app includes other new features, like easy support for PDF or text files within chats, multimodal support on applicable models so users can include images in their prompts, and easily customizable context lengths when working with large documents or chats.
Developers can also use Ollama via command line interface or the app’s software development kit (SDK) to power their applications and workflows.
Other Ways to Use the New OpenAI Models on RTX
Enthusiasts and developers can also try the gpt-oss models on RTX AI PCs through various other applications and frameworks, all powered by RTX, on GPUs that have at least 16GB of VRAM.
NVIDIA continues to collaborate with the open-source community on both llama.cpp and the GGML tensor library to optimize performance on RTX GPUs. Recent contributions include implementing CUDA Graphs to reduce overhead and adding algorithms that reduce CPU overheads. Check out the llama.cpp GitHub repository to get started.
Windows developers can also access OpenAI’s new models via Microsoft AI Foundry Local, currently in public preview. Foundry Local is an on-device AI inferencing solution that integrates into workflows via the command line, SDK or application programming interfaces. Foundry Local uses ONNX Runtime, optimized through CUDA, with support for NVIDIA TensorRT for RTX coming soon. Getting started is easy: install Foundry Local and invoke “Foundry model run gpt-oss-20b” in a terminal.
The release of these open-source models kicks off the next wave of AI innovation from enthusiasts and developers looking to add reasoning to their AI-accelerated Windows applications.
Each week, the RTX AI Garage blog series features community-driven AI innovations and content for those looking to learn more about NVIDIA NIM microservices and AI Blueprints, as well as building AI agents, creative workflows, productivity apps and more on AI PCs and workstations.
Plug in to NVIDIA AI PC on Facebook, Instagram, TikTok and X — and stay informed by subscribing to the RTX AI PC newsletter. Join NVIDIA’s Discord server to connect with community developers and AI enthusiasts for discussions on what’s possible with RTX AI.
Follow NVIDIA Workstation on LinkedIn and X.
See notice regarding software product information.