GraphRAG uses large language models (LLMs) to create a comprehensive knowledge graph that details entities and their relationships from any collection of text documents. This graph enables GraphRAG to leverage the semantic structure of the data and generate responses to complex queries that require a broad understanding of the entire text. In previous blog posts, we introduced GraphRAG and demonstrated how it could be applied to news articles. In this blog post, we show that it can also be tuned to any domain to enhance the quality of the results.
The knowledge graph creation process is called indexing. An LLM, guided by a set of domain-specific prompts, reads all the source content and extracts the relevant information, including entities and relationships, which are then used to construct the graph. For example, when analyzing news articles, entities like people, places, and organizations are important. Here, relationship types might include “lives in,” “leads,” and “owns.”
However, each domain has a different set of entity and relationship types. In the field of chemistry, for instance, entity types include molecules, enzymes, and reactions, while relationship types include “catalyzes” and “reduces.” Although our default news domain prompts in GraphRAG can produce a graph when applied to chemistry, they don’t capture the specific content a chemist would expect.
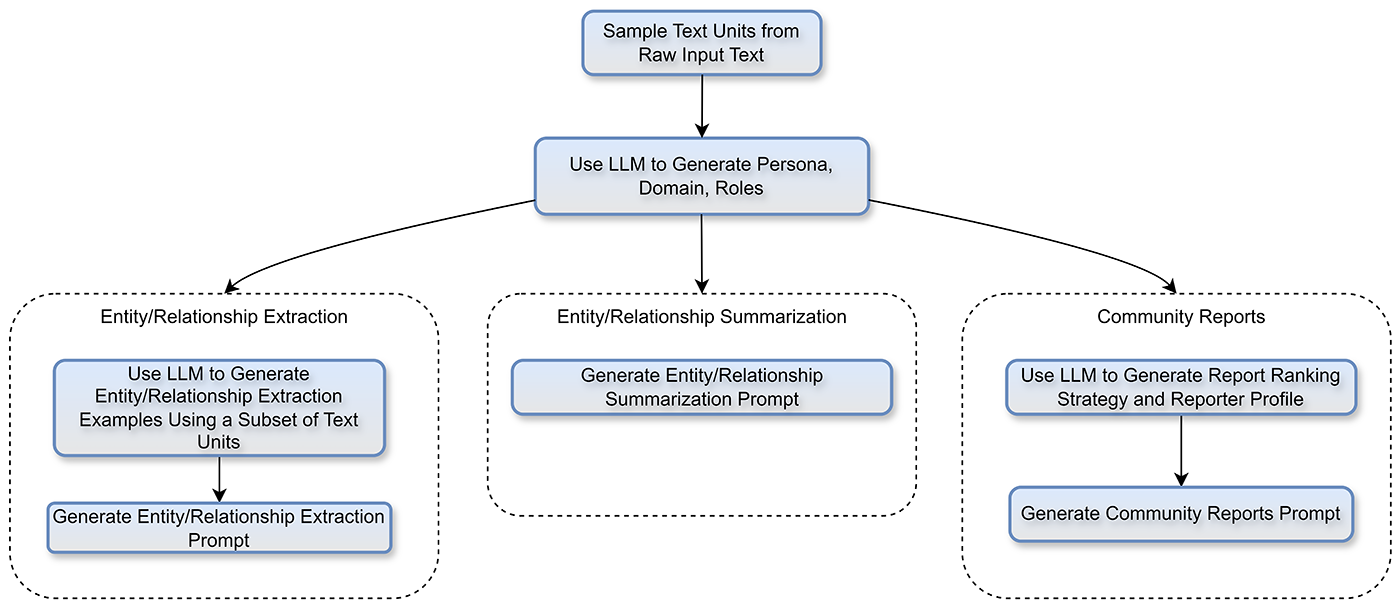
Manually creating and tuning a set of domain-specific prompts is time-consuming. We know, as all the prompts used for news articles were generated manually. To streamline this process, we developed an automated tool that generates domain-specific prompts, which are tuned and ready to use. This tool follows a human-like approach; we provided an LLM with a sample of text data (e.g., 1% of 10,000 chemistry papers) and instructed it to produce the prompts it deemed most applicable to the content. Now, with these automatically generated and tuned prompts, we can immediately apply GraphRAG to a new domain of our choosing, confident that we’ll get high-quality results.
Indexing prompts in GraphRAG
During the indexing process, GraphRAG uses a set of prompts to instruct the LLM as it reads through the source content, extracting and organizing relevant information to construct the knowledge graph. Three of GraphRAG’s main indexing prompts include:
- Entity and relationship extraction: Identifies all the entities present and establishes relationships among them.
- Entity and relationship summarization: Consolidates instances of entities and their relationships into a single, concise description.
- Community report generation: Generates a summary report for each community within the constructed knowledge graph.
These prompts work best when tuned to the domain of the source content. In the rest of this blog post, we focus on domain tuning of the first prompt, “Entity and relationship extraction,” but similar methods apply to the second and third prompts.
Below, Code Sample 1 shows the default few-shot prompt for entity and relationship extraction. This prompt was originally created for news articles and is the default form found in the GraphRAG GitHub repository (opens in new tab). The extraction prompt comprises four sections:
- Extraction instructions: Provide the LLM with guidance on how to perform extraction.
- Few-shot examples: Supply the LLM real examples of the types of entities and relationships worth extracting.
- Real data: Serves as a placeholder that is replaced by chunks of source content.
- Gleanings: Encourage the LLM, over multiple turns, to extract additional information.
The goal of auto-tuning is to create customized few-shot examples that are appropriate for the given domain. The default prompt, shown in Code Sample 1, provides the LLM with fifteen entity examples and twelve relationship examples, but it is notably restricted to just a few specific entity types: organization, geography, and person. These samples were invented by our team and do not represent real entities.
-
Goal
Given a text document that is potentially relevant to this activity and a list of entity types, identify all entities of those types from the text and all relationships among the identified entities.Steps
- Identify all entities. For each identified entity, extract the following information:
- entity_name: Name of the entity, capitalized
- entity_type: One of the following types: [{entity_types}]
- entity_description: Comprehensive description of the entity’s attributes and activities
Format each entity as (“entity“,
, , ) - From the entities identified in step 1, identify all pairs of (source_entity, target_entity) that are *clearly related* to each other.
- source_entity: name of the source entity, as identified in step 1
- target_entity: name of the target entity, as identified in step 1
- relationship_description: explanation as to why you think the source entity and the target entity are related to each other
- relationship_strength: a numeric score indicating strength of the relationship between the source entity and target entity
- Return output in English as a single list of all the entities and relationships identified in steps 1 and 2. Use {record_delimiter} as the list delimiter.
- When finished, output {completion_delimiter}
Format each relationship as (“relationship“,
######################
Examples
######################
Example 1:
Entity_types: ORGANIZATION,PERSON
Text:
The Verdantis’s Central Institution is scheduled to meet on Monday and Thursday, with the institution planning to release its latest policy decision on Thursday at 1:30 p.m. PDT, followed by a press conference where Central Institution Chair Martin Smith will take questions. Investors expect the Market Strategy Committee to hold its benchmark interest rate steady in a range of 3.5%-3.75%.
Output:
(“entity”, CENTRAL INSTITUTION, ORGANIZATION, The Central Institution is the Federal Reserve of Verdantis, which is setting interest rates on Monday and Thursday)
(“entity”, MARTIN SMITH, PERSON, Martin Smith is the chair of the Central Institution)
(“entity”, MARKET STRATEGY COMMITTEE, ORGANIZATION, The Central Institution committee makes key decisions about interest rates and the growth of Verdantis’s money supply)
(“relationship”, MARTIN SMITH – CENTRAL INSTITUTION, Martin Smith is the Chair of the Central Institution and will answer questions at a press conference, 9)
Example 2:
Entity_types: ORGANIZATION
Text:
TechGlobal’s (TG) stock skyrocketed in its opening day on the Global Exchange Thursday. But IPO experts warn that the semiconductor corporation’s debut on the public markets isn’t indicative of how other newly listed companies may perform.
TechGlobal, a formerly public company, was taken private by Vision Holdings in 2014. The well-established chip designer says it powers 85% of premium smartphones.
Output:
(“entity”, TECHGLOBAL, ORGANIZATION, TechGlobal is a stock now listed on the Global Exchange which powers 85% of premium smartphones)
(“entity”, VISION HOLDINGS, ORGANIZATION, Vision Holdings is a firm that previously owned TechGlobal)
(“relationship”, TECHGLOBAL – VISION HOLDINGS, Vision Holdings formerly owned TechGlobal from 2014 until present, 5)
Example 3:
Entity_types: ORGANIZATION,GEO,PERSON
Text:
Five Aurelians jailed for 8 years in Firuzabad and widely regarded as hostages are on their way home to Aurelia.
The swap orchestrated by Quintara was finalized when $8bn of Firuzi funds were transferred to financial institutions in Krohaara, the capital of Quintara.
The exchange initiated in Firuzabad’s capital, Tiruzia, led to the four men and one woman, who are also Firuzi nationals, boarding a chartered flight to Krohaara.
They were welcomed by senior Aurelian officials and are now on their way to Aurelia’s capital, Cashion.
The Aurelians include 39-year-old businessman Samuel Namara, who has been held in Tiruzia’s Alhamia Prison, as well as journalist Durke Bataglani, 59, and environmentalist Meggie Tazbah, 53, who also holds Bratinas nationality.
Output:
(“entity”, FIRUZABAD, GEO, Firuzabad held Aurelians as hostages)
(“entity”, AURELIA, GEO, Country seeking to release hostages)
(“entity”, QUINTARA, GEO, Country that negotiated a swap of money in exchange for hostages)
(“entity”, TIRUZIA, GEO, Capital of Firuzabad where the Aurelians were being held)
(“entity”, KROHAARA, GEO, Capital city in Quintara)
(“entity”, CASHION, GEO, Capital city in Aurelia)
(“entity”, SAMUEL NAMARA, PERSON, Aurelian who spent time in Tiruzia’s Alhamia Prison)
(“entity”, ALHAMIA PRISON, GEO, Prison in Tiruzia)
(“entity”, DURKE BATAGLANI, PERSON, Aurelian journalist who was held hostage)
(“entity”, MEGGIE TAZBAH, PERSON, Bratinas national and environmentalist who was held hostage)
(“relationship”, FIRUZABAD – AURELIA, Firuzabad negotiated a hostage exchange with Aurelia, 2)
(“relationship”, QUINTARA – AURELIA, Quintara brokered the hostage exchange between Firuzabad and Aurelia, 2)
(“relationship”, QUINTARA – FIRUZABAD, Quintara brokered the hostage exchange between Firuzabad and Aurelia, 2)
(“relationship”, SAMUEL NAMARA – ALHAMIA PRISON, Samuel Namara was a prisoner at Alhamia prison, 8)
(“relationship”, SAMUEL NAMARA – MEGGIE TAZBAH, Samuel Namara and Meggie Tazbah were exchanged in the same hostage release, 2)
(“relationship”, SAMUEL NAMARA – DURKE BATAGLANI, Samuel Namara and Durke Bataglani were exchanged in the same hostage release, 2)
(“relationship”, MEGGIE TAZBAH – DURKE BATAGLANI, Meggie Tazbah and Durke Bataglani were exchanged in the same hostage release, 2)
(“relationship”, SAMUEL NAMARA – FIRUZABAD, Samuel Namara was a hostage in Firuzabad, 2)
(“relationship”, MEGGIE TAZBAH – FIRUZABAD, Meggie Tazbah was a hostage in Firuzabad, 2)
(“relationship”, DURKE BATAGLANI – FIRUZABAD, Durke Bataglani was a hostage in Firuzabad, 2)
######################
Real Data
######################
Entity_types: {entity_types}
Text: {input_text}
Output: